
被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路
被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路RL + LLM 升级之路的四层阶梯。
来自主题: AI技术研报
9082 点击 2025-04-24 18:21
 搜索
搜索
RL + LLM 升级之路的四层阶梯。

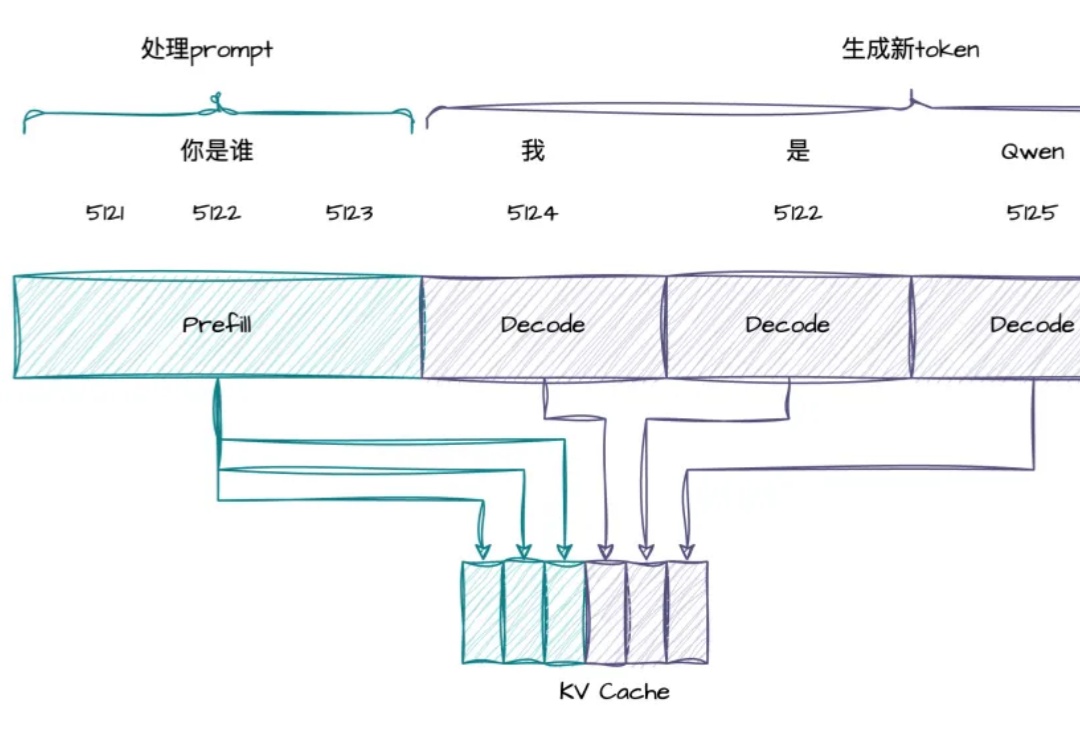
近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?
RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。

强化学习提升了 LLM 各方面的能力,而强化学习本身也在进化。
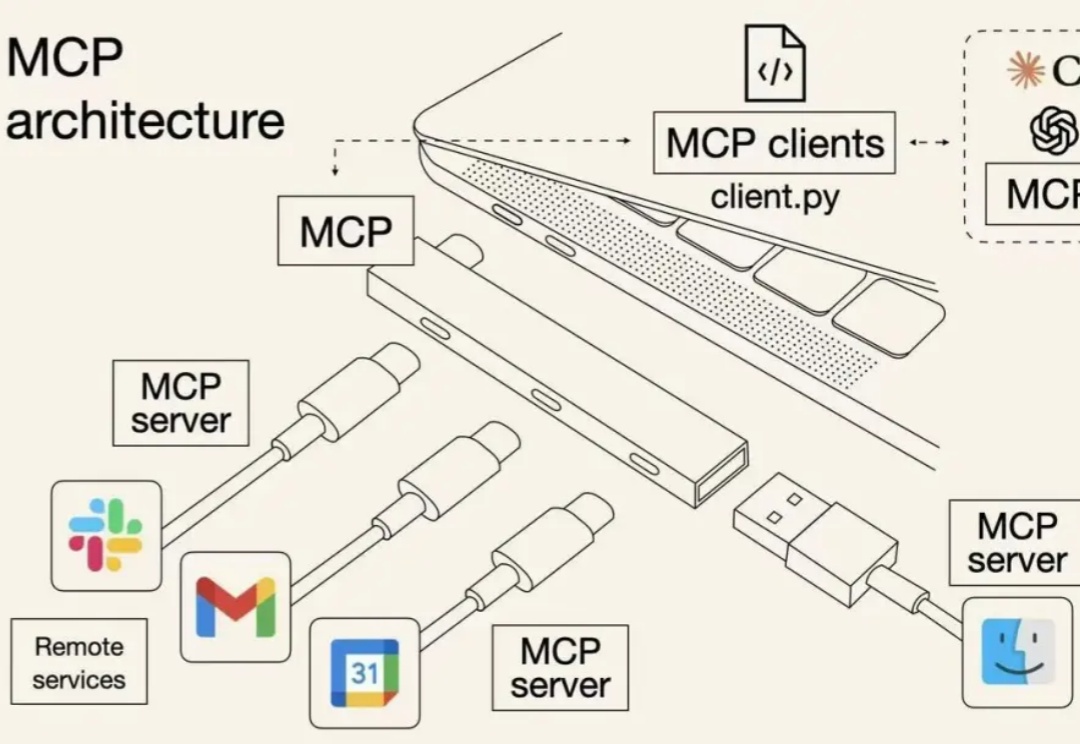
在拾象团队的 2025 的 AI 关键预测中,我们提到:随着 Agent 时代到来,OS 才是 LLM 厂商们最高的护城河,从 computer use 到 MCP,Anthropic 构建 OS 的决心是 AI labs 中最强、最明显的。

清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。

如果你让当今的 LLM 给你生成一个创意时钟设计,使用提示词「a creative time display」,它可能会给出这样的结果:
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。

事关路由LLM(Routing LLM),一项截至目前最全面的研究,来了——
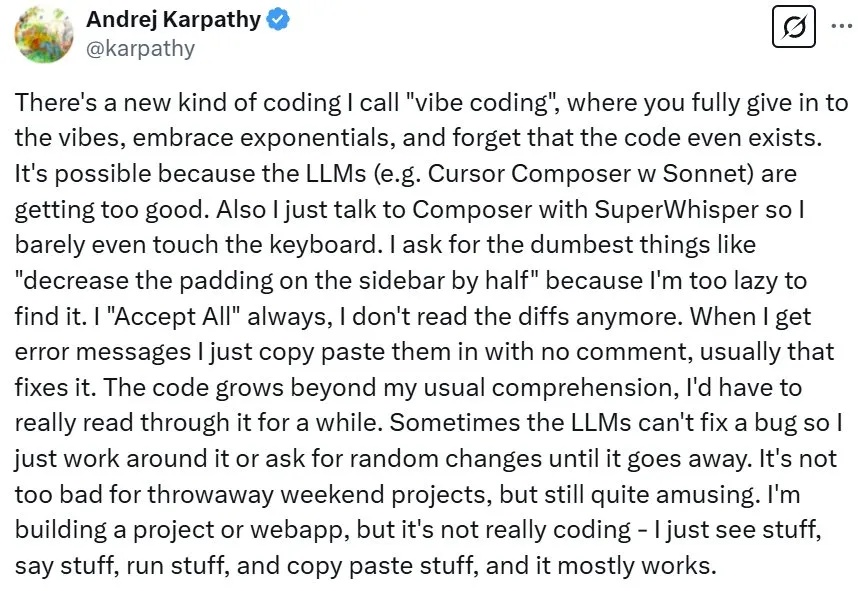
近段时间,著名 AI 科学家 Andrej Karpathy 提出的氛围编程(vibe coding)是 AI 领域的一大热门话题。简单来说,氛围编程就是鼓励开发者忘掉代码,进入开发的氛围之中。更简单地讲,就是向 LLM 提出需求,然后「全部接受」即可。